
Openstack is an open source cloud computing platform, which help to create public and private cloud in large and small scale infrastructure. This technology actually delivers some solutions for cloud servers.
The code developers in the global community software and some cloud specialists equally collaborated to form a new technology known as Openstack. This project aims at simple implementation, massive scalability, and a rich set of features.
Why Openstack?
There are many features to choose the Openstack cloud setup:
1. The main aim of introducing Openstack is to easily manage any type of servers (such as
xen, KVM, etc.) in a single cloud setup.
2. To have the option to setup private or public clouds
3. Can install Openstack in large and small scale as our requirement.
4. The overall setup cost is low. We can build up this cloud setup in single machine too.
5. Simple to integrate in any infrastructure.
6. The servers can easily upgrade the current requirement to higher.
7. The dashboard offers a provision for system administrators to have a look at what is going
on in the cloud, and to manage it as needed.
8. There are built-in storage management tools.
9. Provide a limit in the storage access to users.
10. Set an expiration time for the users.
Components of Openstack Installations:
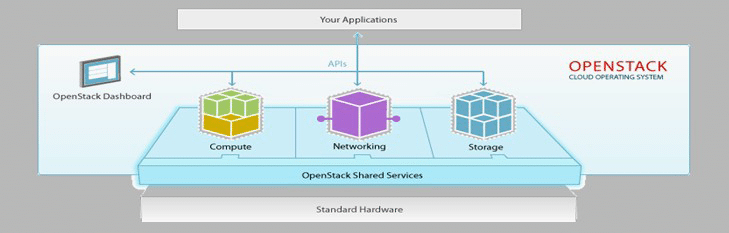
Mainly the Openstack have four different stages of installation:
1. Controller Section
2. Compute Section
3. Networking Section
4. Storage Section
1.Controller Section:
Controller section is one of the important part of Openstack installation. In the OpenStack projects, the API services are controlled by the controller node. The API service of the controller node will help to access all of the components of OpenStack individually for developers as well as administrators.
The modules needed to be installed in the controller node are given below:
a) Databases (with MySQL):
Most of the Openstack components’ data are stored in a relational database. MySQL is commonly used to manage the databases.
b) Keystone (Identity Service):
The keystone is an identity service, which is used by Openstack for authentication. By using the identity service, the users can map to any other Openstack services. This service acts as a common authentication across the whole Openstack cloud setup and can integrate the back-end service like LDAP.
The Openstack supports only two types of authentications:
1. Token-based authentication (authN): This authentication is mainly employed using a token. It allows the users to access specific resources without using any username and password.
2. User-service authentication: These is the authentication, which is employed using username and password.
By using the OpenStack Identity Service, the users can have their own privileges to access the dashboard:
As Administrator:
1. The admin can configure the cloud server policies across users and systems.
2. Can create users and tenants and define permissions for computation, storage and networking of resources, but using the feature of role-based access control (RBAC).
3. Can handle the entire servers built in the openstack.
As a user:
1. Get list of services which the user is using.
2. Log into the Openstack dashboard with separate login credentials and manage the servers and service owned by that particular account.
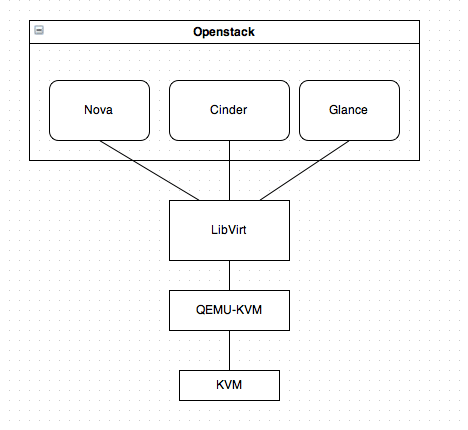
c) Glance (Image Service):
The Glance service is mainly used for discovering, registering and retrieving server images. These images can be used as OS templates to build new virtual servers. The images can be stored at various locations in the server. The image service of the glance API can provide a standard API feature for all the users:
The Administrator can create the templates in the node and make the image as public. So the users can view it and create instances with these templates. The snapshots of the instances also use this image server, but only the administrator and the user who is creating the snapshot can view it.
Below are some formats that allow to upload the private and public images:
• Raw
• Machine (kernel/ramdisk outside of image, a.k.a. AMI)
• VHD (Hyper-V)
• VDI (VirtualBox)
• qcow2 (Qemu/KVM)
• VMDK (VMWare)
• OVF (VMWare, others)
d) Nova (Compute Controller Service):
The Openstack compute service is used to manage the cloud environments such as creation, deletion and scheduling of the instances. We will discuss it on the compute service section.
e) Cinder (Block Storage Service):
The Openstack block service is used to manage the block level storage for the instances. The cinder client in the controller node is used to manage the block storage node.
f) Dashboard (with Horizon):
The Dashboard is a GUI interface to access the provision and automate cloud-based resources which provide a web based user interface to OpenStack services including Nova, Swift, Keystone, etc. The web application allows administrators and users to control their compute instances, storage and resources. The OpenStack Dashboard is a Django-based reference implementation of a web-based management interface for OpenStack.
The Openstack administrator can view the overall functioning of the node servers that are connected with the controller. He can also create users, projects, assign users to projects and set limits on the resources for those projects.
The dashboard provides the users a self-manageable interface for supplying their own resources within the limits set by administrators.
The horizon package in Openstack is used to implement the dashboard in a simple and standard form. With the help of horizon, the web interface became more easy to handle.
Overview of the Openstack Dashboard
How the Controller Works?
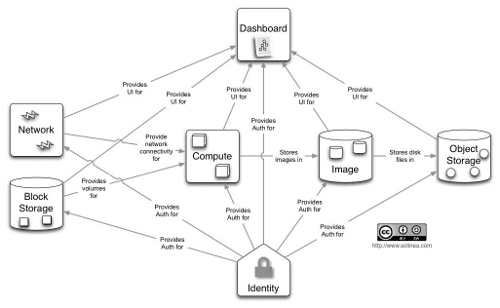
As we already mentioned, the dashboard is the brain of openstack, which produce the request to the other nodes to do the job. The above architecture describes the communication of dashboard with the other services in a functional process.
The identity service authenticates all the requests deployed and forward these requests to its respective services to manage. Finally, the horizon will collect these results and then display them
on the dashboard. The GUI is served by the apache webserver and memcached caching technology, hence loading of the dashboard is pretty faster and there is no scope for lags or glitches. The user can manage the services in Openstack via GUI of the dashboard itself.
2. Compute Section:
Compute nodes have a vital role in Openstack cloud setup. They are the resource core of the OpenStack Compute cloud, providing the processing, memory, network and storage resources to boot up an instance and put it online. The name ‘OpenStack Compute’ refers to a specific project, also called ‘Nova’. Nova is the main service which handles the running of instances and network of the Openstack cloud, but there are really two services that relate to computation and the software that runs it — Image service and Compute:
• Image (glance) manages static disk images which contain the executable code as well as the operating environment.
• OpenStack Compute (Nova) manages the running instances.
Nova controls are the most powerful service compared to the other services in the Openstack family. It uses Keystone service to perform its authentication, Horizon (dashboard) as its administrative interface, and Glance to supply its image templates for the instances at the time of booting an instance.
Working of Nova:
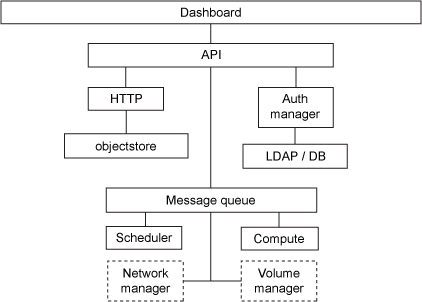
Nova uses an architecture which does not need to share any of the processes from other services to execute its own. Hence, all major components can run on separate servers or like cluster servers, which is the main advantage of the Openstack cloud. Such a feature can decrease server load and can carry out a smooth processing of services with the sufficient memory allocated to it.
The compute node is the hyper-visor node in which we enable various kinds of virtualization technology which you desire to function. A hypervisor provides software to manage virtual machine access to the underlying hardware. Some of the virtualization technologies were mentioned earlier.
KVM is the most widely adopted hypervisor in the OpenStack community. Besides KVM, more deployments run Xen, LXC, VMWare, and Hyper-V than the others listed. However, each of these virtualization is lacking some feature support or the documentation on how to use them with OpenStack.
Nova stores states of VMs in a Mysql database which we create at the time of the nova installation. This database holds details of available instance types, networks details , ID and projects. Launching an instance involves identifying and specifying the virtual hardware templates (called flavors in OpenStack). The templates describe the compute (virtual CPUs), memory (RAM), and storage configuration (hard disks) to be assigned to the VM instances. By default, there are five types of flavors in the Openstack flavor list. We can also add up custom flavors to it according to our need. Then, we can also choose in which compute node the instance must be launched.
After the necessary settings are done, the nova will schedule the requested instance by assigning execution to a specific compute node as chosen at the time of creation.
3. Networking Section
To configure the networking part, the Openstack network node requires two ips,
1) Public ip: to communicate the node with the outside world.
2) Private ip: to communicate between the nodes in the Openstack structure.
There are mainly two methods of networking options in the openstack:
3.1 Nova-Networking: The nova networking method is a simple networking method, which is mostly used for small Openstack cloud foundations. While configuring the network, the nova networking doesn’t need any separate node server to manage, we can install and configure in the compute node itself. The above nova figure shows the working of the nova-networking in the compute node too.
3.2 Neutron: It is an advanced version of the nova-network, which is a software-defined networking for the OpenStack installation. The main advantage of neutron networking is to provide an API that let us define the network connectivity and addressing in the cloud. To configure the neutron in Openstack installation, it is better to use a separate dedicated node server because the neutron server is much complex cluster setup than the nova-network. Mainly this neutron networking is used only on large scale cloud structure.
4. Storage Section
Mainly, the Openstack supports object and block type storages. The object type storage is used to install applications to integrate, used for backup, archiving and data retention. Block storage will reveal and connect to the instance in the compute server for expanding the storage.
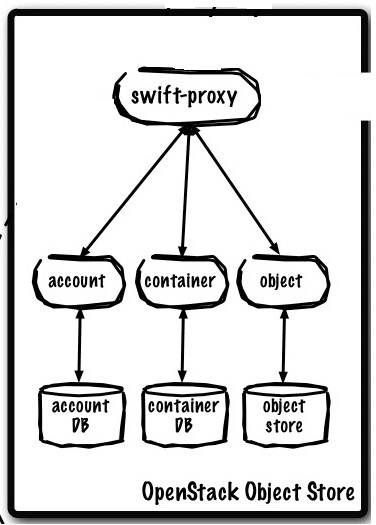
Object Storage Service (Swift Service):
• The Swift storage is a highly durable, scalable object storage system which is designed to store large amount of data in an unstructured manner and at a low cost.
• The data such as objects, files, etc. can be stored in the multiple disk drives spread throughout in the datacenter servers.
• The Openstack softwares provide the disks for the data replication and integrity.
• There we can simply add an extra swift cluster node in the setup without any downtime and compromise on the performance.
• Each developer can interact with this object storage service through a RESTful HTTP API.
• Some of the industrial hardwares are Dell, HP, Supermicro etc.
Working of Swift Service:
The Swift proxy accepts the incoming requests from the controller node, like files to upload, modifications to metadata or container creation; it also serve files and container listing. This request works on three different servers:
1. Account Servers: This server controls the accounts defined with the object storage service.
2. Container servers: It manages a mapping of containers of an instance, folders, within the object store service.
3. Object servers: It manages actual objects, files, on the storage nodes.
Block Storage Service (Cinder Service):
Cinder service is a component of the nova project, which is used to integrate the instances with an extra storage. The type of volume management is also known as nova-volumes.
• Openstack cinder service provides a block level storage device for the use of nove instances.
• This block storage is used to create, manage, attach or detach the storage services on the nova instances.
• The block storage is fully dependant on the Openstack compute service and the dashboard such that the users can manage it easily.
• Apart from Cinder, there are many other services used to handle the storage in the openstack, such as Ceph, NetApp, Nexenta, SolidFire, Zadara, etc.
• The block storage service can be used for the small structure scenarios such as database storage, expandable file system, etc.
• The back up data (known as snapshoting) is also stored in the block storage volumes.
Working of Cinder Services:
The below diagram is a simple architecture of the cinder configuration in Openstack cluster setup. The Cinder/block storage server can be set up in a cluster manner or in a single node manner. It is better to setup or configure the cinder in a dedicated server as we could get the best result out of it. If it’s placed in a single node, the read/write speed of each volume depends upon the whole load of the server, where the other services will be running and eating up the RAM. So if it’s configured in a single server, the workload will be pretty much high.
The basic working of cinder is as follows. When a request is made from the dashboard or common line it communicates with the API, it goes through the relevant authentication manager, connects
the DB where the user details are stored, gets authenticated and reach back to the API. Then, via message service it schedules the process, then contacts the volume services from where the block storage server creates the required volume and provides it as an acknowledgement to the request made and there you get the requested amount of volume created. Now, this volume can be attached to any instances you desire. After attaching the instances, login to it and you need to do the
necessary steps like partitioning and formatting to get it in unstable state.

Conclusion:
The Openstack is a fast growing and a very solid cloud based technology, which holds various features for simplifying and standardizing both public clouds and enterprise private clouds. The
main feature of Openstack is to install the clustering services in a small scale and large scale base. As of now, more and more companies begin to adopt OpenStack as a part of their cloud toolkit. The new OpenStack Icehouse is available, which contains nearly 350 new features to support software development, managing data and application infrastructure at scale. The OpenStack community still continues to develop new features thereby making the technology stronger.
Reference:
http://docs.openstack.org/icehouse/install-guide/install/yum/content/
http://docs.openstack.org/grizzly/openstack-compute/install/yum/content/
https://ask.openstack.org/en/questions/





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}