
1. Hadoop common: Contain utilities and libraries needed by other Hadoop modules.
2. HDFS(Hadoop Distributed File System): a distributed file system that stores data and provides a high bandwidth across clusters.
3. Hadoop YARN: a resource management platform that is responsible for managing resources in cluster.
4. Hadoop MapReduce: a programming model for large scale data processing.
All these modules are designed with the assumption that hardware failures in systems are common and these are automatically handled by software in framework. Eventhough Hadoop stores enormous data cheaply, the computations it enables with MapReduce are highly limited. This module is only able to execute simple calculations. So as an alternative to Hadoop, Apache’s Spark developed, offering functionalities like stream processing, unlimited computations etc.. Spark cannot be considered as an replacement to Hadoop, but as an alternative to Hadoop MapReduce. In addition to MapReduce operations, it supports SQL queries, streaming data, machine leaning and graph data processing.
The main advantage of Spark is that it is 100% compatible with the Hadoop modules, including Hadoop file system(HDFS) and storage. It can execute jobs 100 times faster than Hadoop. Some of the advantages of Spark over Hadoop’s MapReduce model are:
i. Faster and large data processing: The main advantage of Spark compared to Hadoop is its high speed as it can execute batch processing jobs 100 times faster than the MapReduce model, which Hadoop uses. This makes Spark suitable for large applications that require low latency queries,iterative computations etc…
ii. Real time stream processing: Instead of just processing some stored data(as in the case of Hadoop MapReduce), Spark is able to manipulte the data in real time. In addition to stream processing, Spark can also be used with existing machine learning code libraries, which allows machine learning to be carried out on data stored in Hadoop clusters.
iii. Easy to manage: Since Spark can carry out streaming on the same cluster of data, several organizations are able to simplify their infrastructure used for data processing. Today, most of the companies use the Hadoop Mapreduce model to generate report and a separate system for stream processing. This requires managing and maintaining two different systems. Implementing both batch and stream processing on top of Spark avoids this complexity.
Spark Architecture
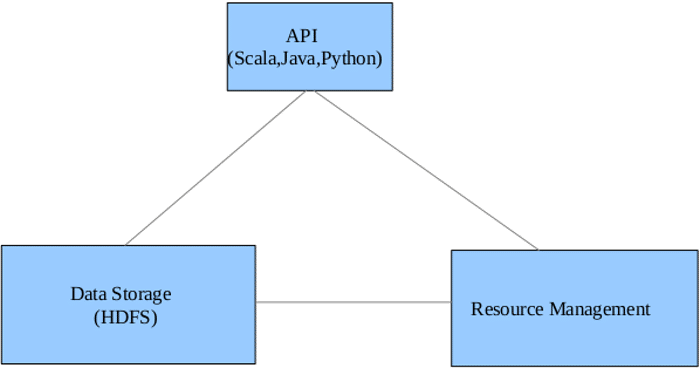
Spark is composed of the following 3 components:
- Data Storage: For data storage purposes, Spark uses HDFS file system.
- API: This allows developers to create Spark based applications using an API interface. Three interfaces are available- Scala API, Java and Python.
- Resource Management: Spark can either be developed as a Stand-alone server or can be on a distributed framework.
Spark Installation
The code for installing Apache Spark can be downloaded from http://spark.apache.org/, based on the version of Hadoop on your system. Installation involves just unzipping the downloaded file. Here, we are installing Spark as a stand-alone server.
$ cd /home/
$ wget http://www.gtlib.gatech.edu/pub/apache/spark/spark-1.3.1/spark-1.3.1.tgz
$ tar -xvf spark-1.3.1.tgz
You can start a standalone master by using the following command:
$ cd spark-1.3.1
$ ./sbin/start-master.sh
Once the master is started, it will print out a URL(spark://HOST:PORT), which can be used to connect host/workers to the master. This URL can also be found on http://localhost:8080, which is the default master’s web UI.
Similarily, we can install and start Spark on one or more workers and connect them to the master by:
$ ./bin/spark-class org.apache.spark.deploy.worker.Worker spark://HOST:PORT
Once a worker is started, check the master web interface. You can see the new node there, along with its number of CPUs and memory, listed. If we need to launch Spark using certain launch scripts, create a file called conf/slaves in the Spark directory. This file should contain the hostnames of all the machines containing workers, one per line. The master machine also must be able to access each of the workers using a private key(password-less ssh).
Once this file is setup, we can start/stop the cluster with the following scripts:(in /sbin directory of spark folder) ./sbin/start-master.sh : Starts a master instance on the machine the script is executed on.
./sbin/start-slaves.sh : Starts a slave instance on each machine specified in the slaves file.
./sbin/start-all.sh : Starts both a master and a number of slaves as described above.
./sbin/stop-master.sh : Stops the master that was started via the./sbin/start-master.sh
./sbin/stop-slaves.sh : Stops all slave instances on the machines specified in the slaves file
./sbin/stop-all.sh : Stops both the master and the slaves as described above.
There is another way of configuring cluster, that is by creating a file conf/spark-env.sh. However, this is optional.
cd conf
$ touch spark-env.sh
$ mv spark-env.sh.template spark-env.sh
We need to copy this file to all the worker machines for the settings to take effect.
In order to run an application on the Spark standalone cluster, pass the URL spark://IP:PORT of the master to SparkContext Constructor. Spark also provides an interactive shell, that helps in analyzing the data interactively. It is available in both Scala and Java API, and can be started by running the following command:
./bin/spark-shell –master spark://IP:PORT
One thing to note here is that if we are running this spark-shell script from one of the spark cluster machines, the script will automatically set master from the SPARK_MASTER_IP and SPARK_MASTER_PORT variables in spark-env.sh file Spark also offers a web-based user interface for monitoring the cluster. Both master ans workers have their own interfaces showing cluster and job statistics.
If we have an existing Hadoop cluster, Spark can be used alongside this by just launching it as a separate service on the same machines. To access Hadoop data from Spark, just use a hdfs://<namenode>:9000/path (If you are not sure about the exact URL, it can be obtained on Hadoop namenode’s UI). The primary ports that Spark uses for its communication are 8080,4040,18080,8081,7077.
Future of Spark
About the quarter of 2014, Apache Spark came superior to Hadoop. This sudden change is widening the gap between Spark and Hadoop. Spark replaces Hadoop Mapreduce model which makes it a simpler structure. But one thing to be noted here is that Spark isn’t inherently competitive with Hadoop-infact it was designed to work with Hadoop’s filesystem. Spark has made it as a top-level Apache project. It is also Apache’s most active project with hundreds of contributors. Keeping that in mind, Spark will have a bright future.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}